


Web Scraping with JavaScript: An Introduction
Contents
When it comes to the most commonly used programming language for web scraping, Python often comes out on top due to its rich ecosystem of web scraping libraries and ease of use. Its syntax is very easy to read, making it fast for anyone to pick up the language.
That said, other programming languages can also be used for web scraping. One of them is JavaScript. In this article, we’ll explore how to use JavaScript for web scraping, including using libraries like Cheerio, Puppeteer, Nightmare, Playwright, and API like Browserbear.
What is Web Scraping
Web scraping is a way to extract data and information from a website automatically using tools. It is usually used when the amount of data to be retrieved from a website is vast and can’t be done with manual effort.
Web scraping can be used for a variety of purposes, such as gathering data for market research, monitoring competitor prices, analyzing sentiment on social media, collecting news articles, and more. As it can be executed automatically, it can save you so much time and effort as compared to collecting the data manually.
Python vs. JavaScript: Which is Better for Scraping
Both Python and JavaScript can be used for web scraping, and each language has its own capabilities:
Python is a popular choice for web scraping due to its rich ecosystem of web scraping libraries, such as Beautiful Soup, Scrapy, and Selenium. These libraries simplify the data scraping process and help you extract data from websites easily. Besides that, Python is also known for its ease of use and readability, making it a good choice for beginners who want to learn how to scrape a website.
🐻 If you want to learn how to scrape a website using Python, read Web Scraping with Python: An Introduction and Tutorial.
JavaScript is also a good choice for web scraping, particularly for tasks that require interaction with dynamic web pages that use JavaScript. As it is the primary language of the web, it can be a good choice for developers who are already familiar with JavaScript and want to use it for web scraping.
It has many libraries that can be used for web scraping too. Let's see what they are.
Web Scraping Libraries for JavaScript
Cheerio
Cheerio is a fast and flexible library for parsing and manipulating HTML and XML. It does not produce a visual rendering, apply CSS, load external resources, or execute JavaScript. Therefore, it is extremely fast compared to other libraries. However, this is also something to take note of—if you need to scrape data that require these resources, other web scraping libraries could be a better choice.
After parsing HTML or XML using Cheerio, you can extract data from it using the jQuery syntax. Here’s a simple example:
// ES6 or TypeScript:
import * as cheerio from 'cheerio';
// In other environments:
const cheerio = require('cheerio');
cheerio.load('<ul id="fruits"><li class="apple">Apple</li>...</ul>', null, false);
$.html();
//=> '<ul id="fruits">...</ul>'
$('.apple', '#fruits').text();
//=> Apple
To visit a URL, make an HTTP request to the URL using Fetch or Axios:
const response = await axios.get("https://www.browserbear.com");
// Get the HTML code of the webpage
const html = response.data;
const $ = cheerio.load(html);
Puppeteer
Puppeteer is a Node.js library that provides a high-level API for controlling headless Chrome or Chromium browsers. Besides web scraping, it can also be used for other tasks that can be automated on a browser such as testing, generating PDFs, taking screenshots, downloading images, and more.
Typically, you’ll need to use Puppeteer to launch a Chrome or Chromium browser and instruct it to carry out actions like navigating to a URL, typing into a search box, clicking on a link, etc. to perform a task. Then, you can scrape the data by querying the relevant HTML elements using CSS selectors.
Here’s an example from Puppeteer’s official documentation that goes to a URL, searches a text, and prints out the title of the selected search result:
import puppeteer from 'puppeteer';
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://developer.chrome.com/');
// Type into search box
await page.type('.search-box__input', 'automate beyond recorder');
// Wait and click on first result
const searchResultSelector = '.search-box__link';
await page.waitForSelector(searchResultSelector);
await page.click(searchResultSelector);
// Locate the full title with a unique string
const textSelector = await page.waitForSelector(
'text/Customize and automate'
);
const fullTitle = await textSelector.evaluate(el => el.textContent);
// Print the full title
console.log('The title of this blog post is "%s".', fullTitle);
await browser.close();
})();
Nightmare
Nightmare is a high-level browser automation library from Segment that uses Electron under the hood. It provides an easy-to-use API for interacting with web pages and can be used for automation tasks such as those that have been mentioned previously in this article. Among all things that it can do, people most often use it for UI testing and web crawling.
Here's a simple script to open a web page and extracts the H1:
import Nightmare from 'nightmare';
const nightmare = Nightmare();
const selector = 'h1'
nightmare.goto('https://www.browserbear.com')
.evaluate(selector => {
return document.querySelector(selector).innerText
}, selector)
.then(text => {
// ...
})
As Nightmare uses Document.querySelector() to look for an HTML element, you can extract data from any HTML element that can be located using appropriate CSS selectors.
Playwright
Playwright is a relatively new web automation library developed by Microsoft that allows developers to control modern web browsers like Chromium, Firefox, and WebKit using a simple and intuitive API. With Playwright, you can easily automate browser interactions to scrape data from websites and also do other tasks like carrying out tests for your web application.
Playwright works similarly to Puppeteer. First, you will need to launch a browser and navigate to a URL. Then, use CSS selectors to locate the target HTML element and retrieve its text or link.
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://www.browserbear.com/blog');
const titles = await page.evaluate(() => {
const articles = Array.from(document.querySelectorAll('.article'));
const titles = articles.map((article) => article.querySelector('h2').textContent);
return titles;
});
console.log('Titles:', titles);
await browser.close();
})();
Although Playwright and Puppeteer seem similar, one significant difference is that Playwright supports multiple browsers, while Puppeteer is limited to Chromium/Chrome only. This makes Playwright a more versatile tool compared to Puppeteer.
Web Scraping without a Library (Browserbear API)
Besides using libraries like Cheerio, Puppeteer, Nightmare, and Playwright, you can also scrape a website without using one. One way to do so is by using an API like Browserbear.
Browserbear is a scalable, cloud-based browser automation tool that helps you to automate any browser task, including web scraping. For every automation, you will need to create a task in the Browserbear dashboard (creating a trial account is free). Then, you can send HTTP requests to the Browserbear API to trigger the task and receive the data.
When you create a task in the Browserbear dashboard, you need to add steps to the task. Browserbear will execute each step to complete the task. Your task should look like this and you can click the “Run Task” button to execute it manually.
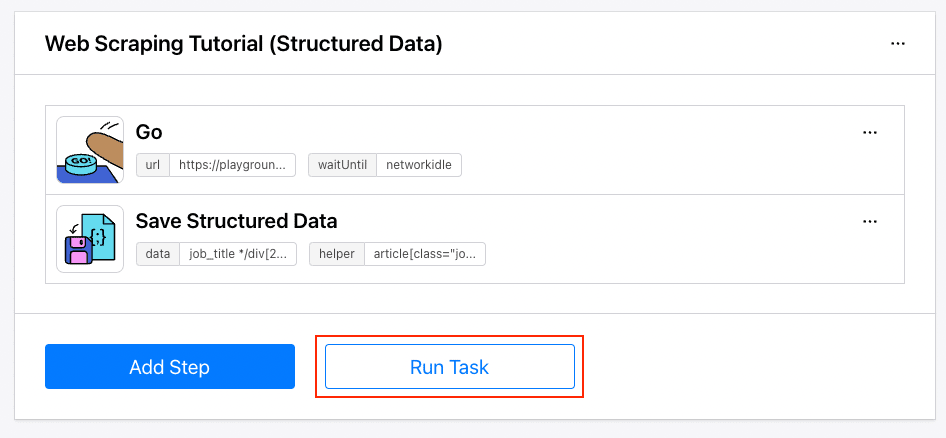
After you have tested that the task can be run successfully, you can use it in your JavaScript code, without having to install any additional library.
You can run the task by making a POST request to the Browserbear API with the task's ID:
async function runTask(body) {
const res = await fetch(`https://api.browserbear.com/v1/tasks/${TASK_UID}/runs`, {
method: 'POST',
body: body
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${API_KEY}`,
},
});
return await res.json();
}
const run = await runTask(body);
There are two ways to receive the result: by using a webhook or making continuous GET requests to the Browserbear API (API polling).
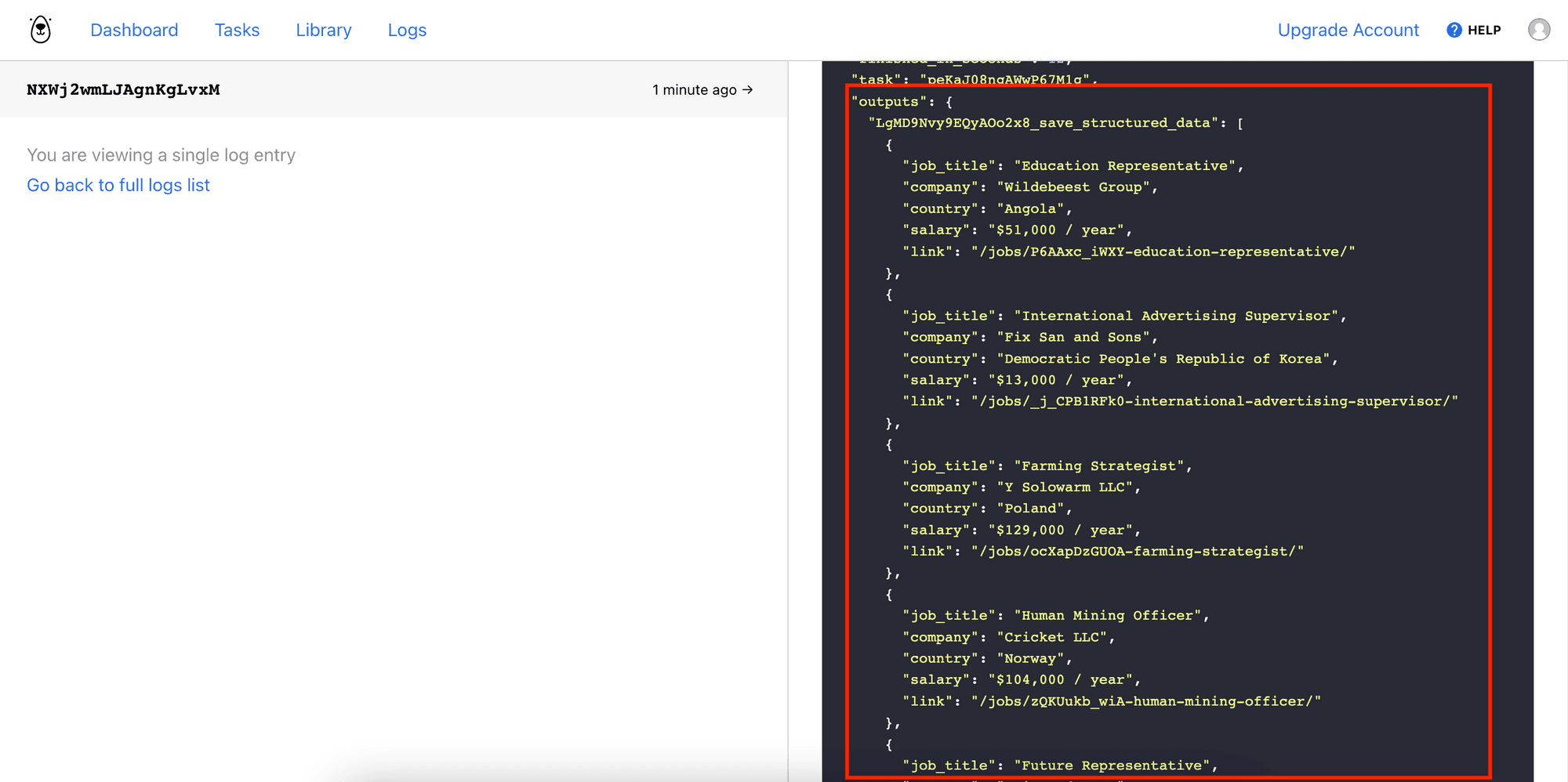
After receiving the result, you can find the scraped data in the outputs array, named in the format of [step_id]_save_structured_data:
...
"outputs": {
"[step_id]_save_structured_data" :[
{
job_title: 'Education Representative',
company: 'Wildebeest Group',
location: 'Angola',
link: '/jobs/P6AAxc_iWXY-education-representative/',
salary: '$51,000 / year'
},
{
job_title: 'International Advertising Supervisor',
company: 'Fix San and Sons',
location: "Democratic People's Republic of Korea",
link: '/jobs/_j_CPB1RFk0-international-advertising-supervisor/',
salary: '$13,000 / year'
},
{
job_title: 'Farming Strategist',
company: 'Y Solowarm LLC',
location: 'Poland',
link: '/jobs/ocXapDzGUOA-farming-strategist/',
salary: '$129,000 / year'
}
...
]
}
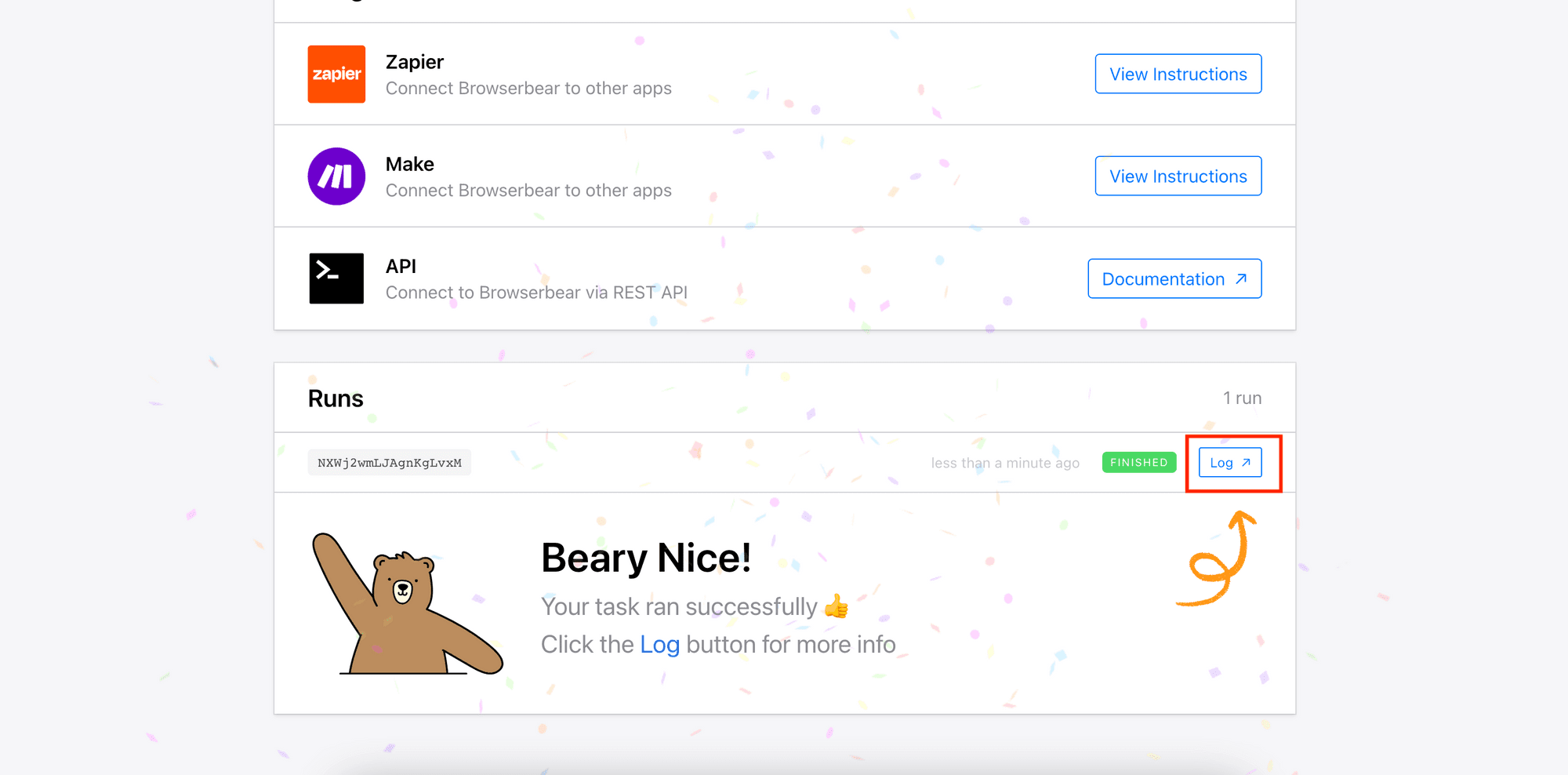
You can also find the same result in your Browserbear dashboard, under the run’s “Log”:
For the detailed tutorial on how to scrape a website in JavaScript using Browserbear, read:
👉🏻 How to Scrape Data from a Website Using Browserbear (Part 1)
👉🏻 How to Scrape Data from a Website Using Browserbear (Part 2)
Conclusion
Both Python and JavaScript are powerful languages with a rich set of libraries for web scraping. Ultimately, you should decide which programming language to use based on your web scraping goals so that it is best suited for the task at hand. Last but not least, choosing a programming language that you are more familiar with can also shorten the learning curve. Happy scraping!
