


Web Scraping with ChatGPT API and Browserbear (Python Example)
Contents
Since the rollout of ChatGPT, there has been a growing interest in using it for various kinds of tasks to improve efficiency. The current paid version of ChatGPT, ChatGPT Plus has introduced many features that are exclusive to the subscribers like creating custom GPTs, optimized performance, web browsing, and more. However, when integrating ChatGPT into your application, certain features, like web browsing, are not directly available through the API.
To overcome this limitation, we can browse the target website and scrape data from it using Browsebear, a cloud-based browser automation tool. Then, use ChatGPT API to read the scraped data and perform various tasks like data analysis, text summarization, sentiment analysis, and more. In this tutorial, we'll show you how to scrape data from a job board using Browserbear, and utilize ChatGPT API to analyze the data and get insights like the number of jobs, average salary, etc.
What is Browserbear
Browserbear is a scalable, cloud-based browser automation tool that helps you automate browser tasks. You can use it to automate website testing, scrape data from websites, take scheduled screenshots for archiving, and more without writing a single line of code.
Unlike other web automation tools that require coding, Browserbear is incredibly simple to set up and use. You can easily locate your target HTML element (the blue box in the screenshot below) by hovering your mouse over it with the Browserbear Helper extension…
… and add necessary steps to your automation task from the Browserbear dashboard.

There are two ways to run a task: run it directly from the account dashboard, or use the API (if you want to integrate it into coding projects). And we'll be using the API in this tutorial.
What Is the ChatGPT API? How Is It Different from ChatGPT?
The ChatGPT API enables developers to access the functionalities of ChatGPT, the conversational AI model, and integrate it into their applications and websites. Different from using the ChatGPT chat interface, the API provides more flexibility with integration ability.
While ChatGPT Plus offers a chat interface with built-in features like integrated browsing, code execution, plugins, etc., the API offers developers the flexibility to create custom interfaces and functionalities tailored to their specific needs. It can be integrated into applications to build chatbots, assistants, and other tools.
Here are some real-life examples:
- Snapchat uses the ChatGPT API to build a customizable chatbot that offers recommendations and answers all types of questions.
- Instacart uses the ChatGPT API alongside its own AI and product data from its 75,000+ retail partner store locations to help customers discover shopping ideas and get personalized suggestions.
- Shopify uses the ChatGPT API to power Shop’s (Shopify’s consumer app) shopping assistant, which provides personalized recommendations based on shoppers' requests.
(Reference: https://openai.com/blog/introducing-chatgpt-and-whisper-apis)
Setting up a Web Scraping Task in Browserbear
We will scrape information like job title, company name, salary, and location from this job board for this tutorial:

Browserbear has an AI web scraper that scrapes data based on your input. All you need to do to scrape information from a website is enter the website URL, type of data (jobs/articles/products/people/places), and fields that you want to scrape (eg. job title, company name, salary, etc.) and click the “Start Scraping” button:
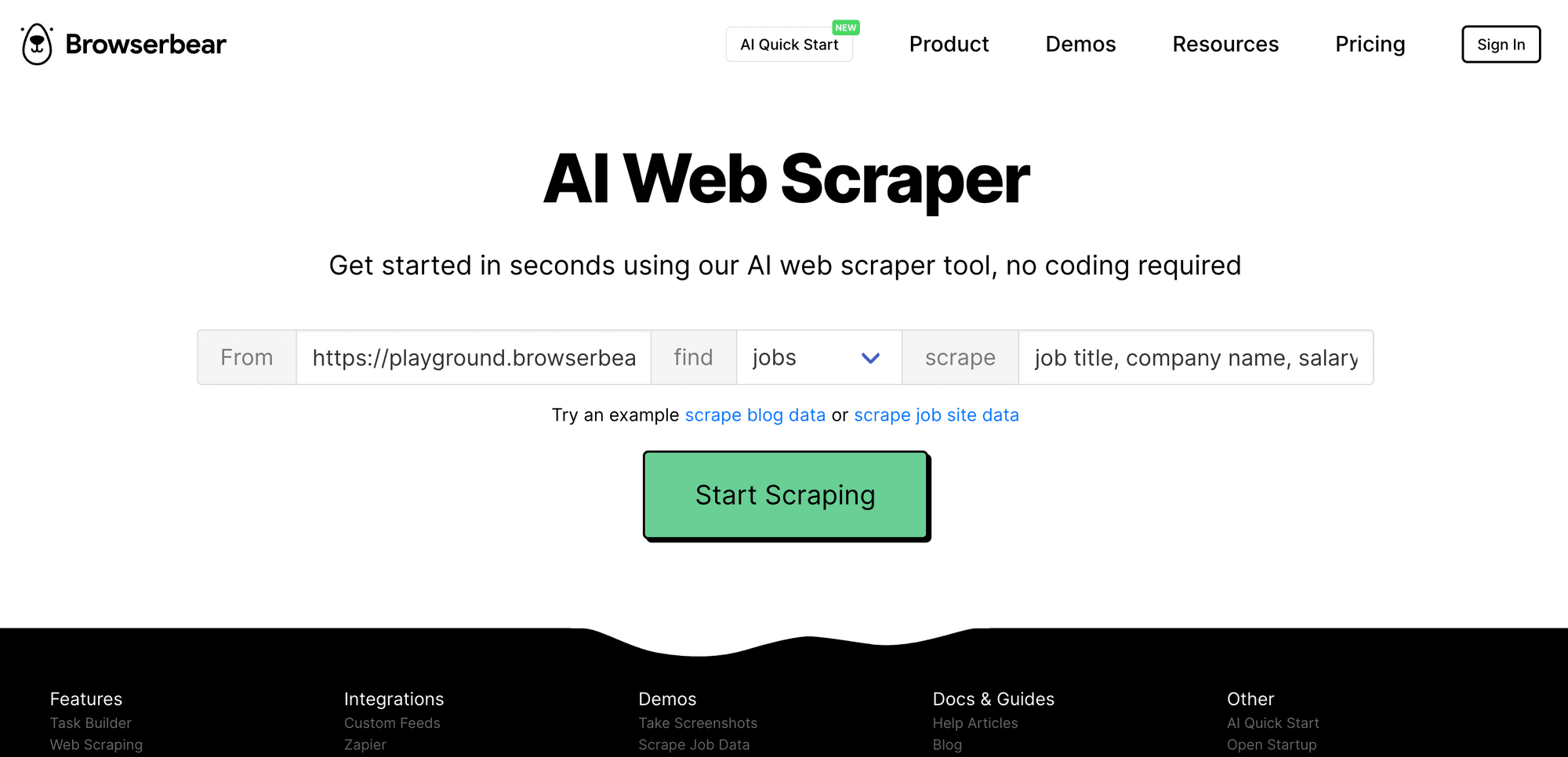
If you’re not logged in to a Browserbear account, you’ll be prompted to create one. Simply sign up for an account (it’s free!) to continue:
If you’re logged in to your account, you’ll be able to see the task running in your account:
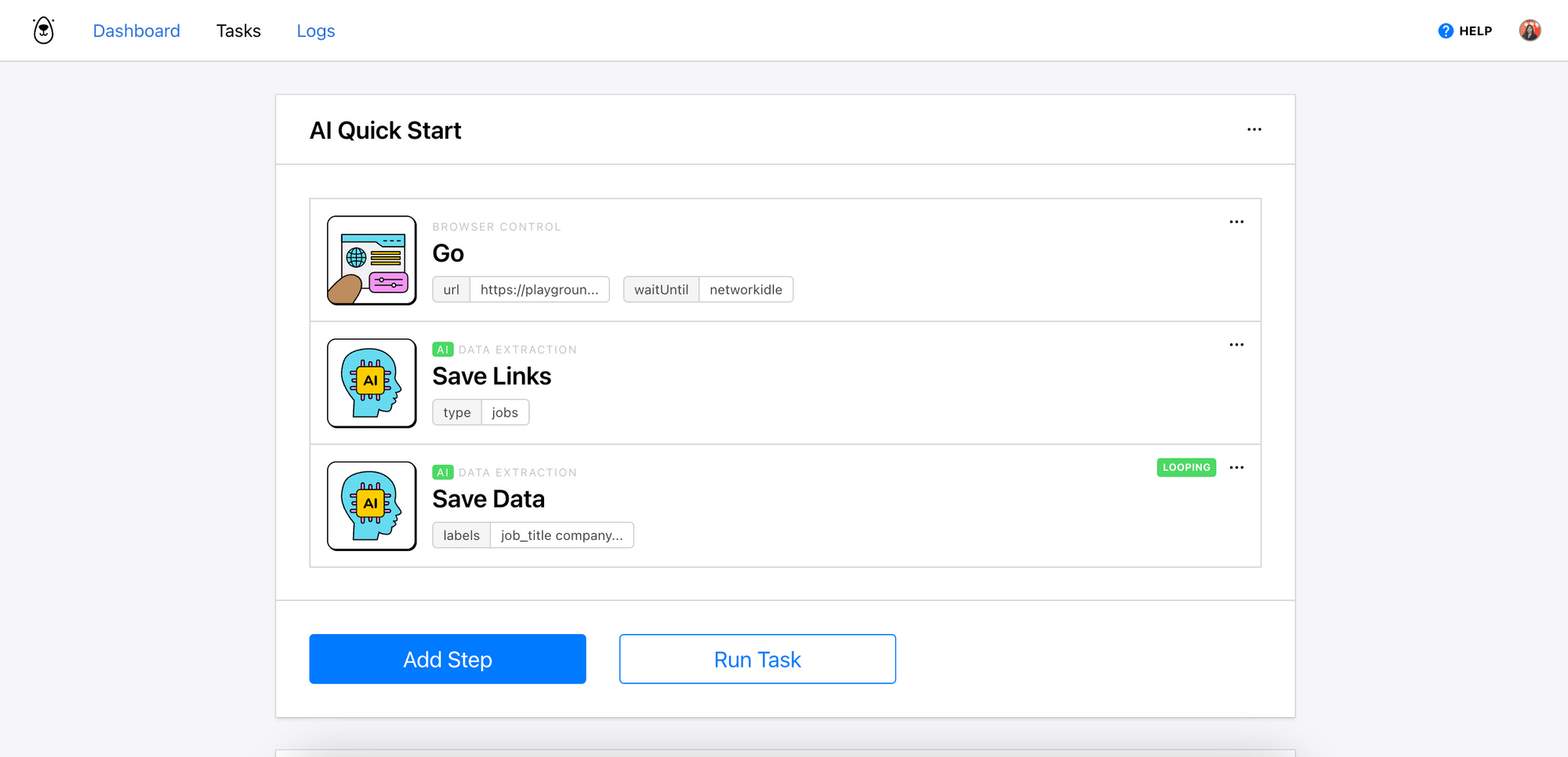
You can also run the task manually by clicking the “Run Task” button:

Scroll down to the bottom of the page to check the progress. After the task has finished running, the result can be found in the log:

As we want to feed the scraped data to ChatGPT API in our Python project, we need the Browserbear project’s API key , task ID , and result ID to access the task and the result. You can find them from your account, as shown in the screenshots below:



Copy and save them somewhere safe. We will use them in our code later to scrape data.
🐻 Bear Tips: If you want more control over which HTML element to scrape the data from, you can create a web scraping task in Browserbear manually (doesn’t use AI). Read How to Scrape Data from a Website Using Browserbear to learn how.
Getting the ChatGPT API Key
To use the ChatGPT API in our Python project, sign up for an OpenAI account and log in to the API dashboard.

Then, go to the “API Keys” tab and click “Create new secret key” to create a new secret/API key.

Like before, copy the key and save it somewhere safe.
Python Code
After setting up a web scraping task in Browserbear and retrieving the required API keys and IDs, it’s time for coding! If you don’t have an existing project/script, create a file for writing the code (eg. script.py). Then, follow the steps below:
Step 1. Install the OpenAI Python Library
Run the command below in your terminal/command line to install the OpenAI Python library:
pip install --upgrade openai
Note: If you’re using Python 3.x, replace pip in the command above with pip3.
Step 2. Import the OpenAI Python Library and Declare Required Constants
In your code, import requests, OpenAI, and json:
import requests
from openai import OpenAI
import json
… and declare the following constants using your API keys and relevant IDs:
SCRAPING_TASK_UID = "your_browserbear_task_id"
BROWSERBEAR_API_KEY = "your_browserbear_api_key"
BROWERBEAR_RESULT_UID = "your_browserbear_task_result_id"
OPENAI_API_KEY = "your_openai_api_key"
🐻 Bear Tips: To protect the private keys and IDs, it’s best to save them as environment variables in a
.envfile and retrieve them usingos.environ.get( “VARIABLE_NAME”).
Then, create a new instance of OpenAI:
client = OpenAI(api_key=OPENAI_API_KEY)
Step 3. Scrape Data Using Browserbear API
Define a function named scrape_data() and send a POST request to Browserbear inside the function to trigger the task. As Browserbear API allows us to pass data (URL, type of job, fields to extract) to the task to reuse it for different websites and scrape different fields, let's define the function to take in parameters like target_url, job_type, and fields_array so that we can use it for other websites too:
def scrape_data(target_url, job_type, fields_array):
url = f"https://api.browserbear.com/v1/tasks/{SCRAPING_TASK_UID}/runs"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BROWSERBEAR_API_KEY}",
}
search_fields = ""
for i, field in enumerate(fields_array):
search_fields += f"{field}\n" if i != len(fields_array)-1 else field
data = {
"steps": [
{
"uid": "1RNV0rb0dQwbOxmQ6X",
"action": "go",
"config": {
"url": target_url,
"waitUntil": "networkidle"
}
},
{
"uid": "qL25wVyl6gdzE4mJ1x",
"action": "ai_save_links",
"config": {
"type": job_type
}
},
{
"uid": "lYXA8Kz19QDzLV94N7",
"action": "ai_save_data",
"config": {
"labels": search_fields
}
}
]
}
response = requests.post(url, headers=headers, json=data)
print(f"Scraping {fields_array} from {target_url}...")
return response.json()
scraping_task = scrape_data("https://playground.browserbear.com/jobs/", "jobs", ["job_title", "company_name", "salary", "location"]) # scraping jobs
Note: Replace the IDs in the data object with your task’s steps’ actual IDs.
You can use the same task to scrape products and articles too:
# scraping_task = scrape_data("https://playground.browserbear.com/products/", "produtcs", ["title", "price", "rating"]) # scraping products
# scraping_task = scrape_data("https://www.browserbear.com/blog/", "articles", ["title", "author", "description"]) # scraping articles
Step 4. Retrieve the Web Scraping Result
Next, create a function named get_scraped_data() and send a GET request to Browserbear inside the function to retrieve the web scraping result. As the task might take a while to complete, we will poll the result by sending continuous API requests to Browserbear until the result is returned:
def get_scraped_data(result_uid):
job_status = "running"
result = ""
get_url = f"https://api.browserbear.com/v1/tasks/{SCRAPING_TASK_UID}/runs/{result_uid}"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BROWSERBEAR_API_KEY}",
}
while job_status == "running":
response = requests.get(get_url, headers=headers)
result = response.json()
job_status = result["status"]
return result["outputs"][BROWERBEAR_RESULT_UID]
data = get_scraped_data(scraping_task["uid"])
print(data)
Here’s an example of the data returned:
[
{
"link": "https://playground.browserbear.com/jobs/7dJRGX9wgRQ-farming-executive/",
"job_title": "Farming Executive",
"company": "Job Inc",
"salary": "$113,000 / year ",
"location": "Fiji"
},
{
"link": "https://playground.browserbear.com/jobs/9XxqTZH25WQ-accounting-orchestrator/",
"job_title": "Accounting Orchestrator",
"company": "Mat Lam Tam Group",
"salary": "$15,000 / year ",
"location": "Israel"
},
{
"link": "https://playground.browserbear.com/jobs/0fIJzIQwf0c-central-accounting-developer/",
"job_title": "Central Accounting Developer",
"company": "Home Ing and Sons",
"salary": "$10,000 / year ",
"location": "Afghanistan"
},
...
]
Step 5. Using ChatGPT API to Analyze the Data
Now, we can pass the scraped data to ChatGPT API in an array of message objects. Each object has a role (system/user/assistant) and content, and the array typically starts with a system message, followed by alternating user and assistant messages.
Let’s prepare an array of message objects that contain the scraped data and some questions for ChatGPT and add it to our code:
# Set up the initial system message
system_message = {"role": "system",
"content": "You are a helpful assistant that analyzes information. Analyze this data and answer my questions based on the data:" + json.dumps(data)}
# Start the conversation with the system message
conversation = [system_message]
# Add user message to the conversation
user_message = {"role": "user", "content": "How many jobs are there? What are the jobs with the top 5 highest salary? What is the average salary?"}
conversation.append(user_message)
Then, make a request to the Chat Completion API:
# Pass data to ChatGPT and get the response
response = client.chat.completions.create(model="gpt-4-1106-preview", messages=conversation)
# Extract and print the assistant's reply
assistant_reply = response.choices[0].message.content
print(f"Assistant: {assistant_reply}")
You can choose which ChatGPT model to use and the cost is different for every model (ChatGPT API cost). For this tutorial, we're using ChatGPT 4 (gpt-4-1106-preview).
The code is complete! When you run python script.py or python3 script.py to execute it, you will see ChatGPT’s answer in the terminal/command prompt :
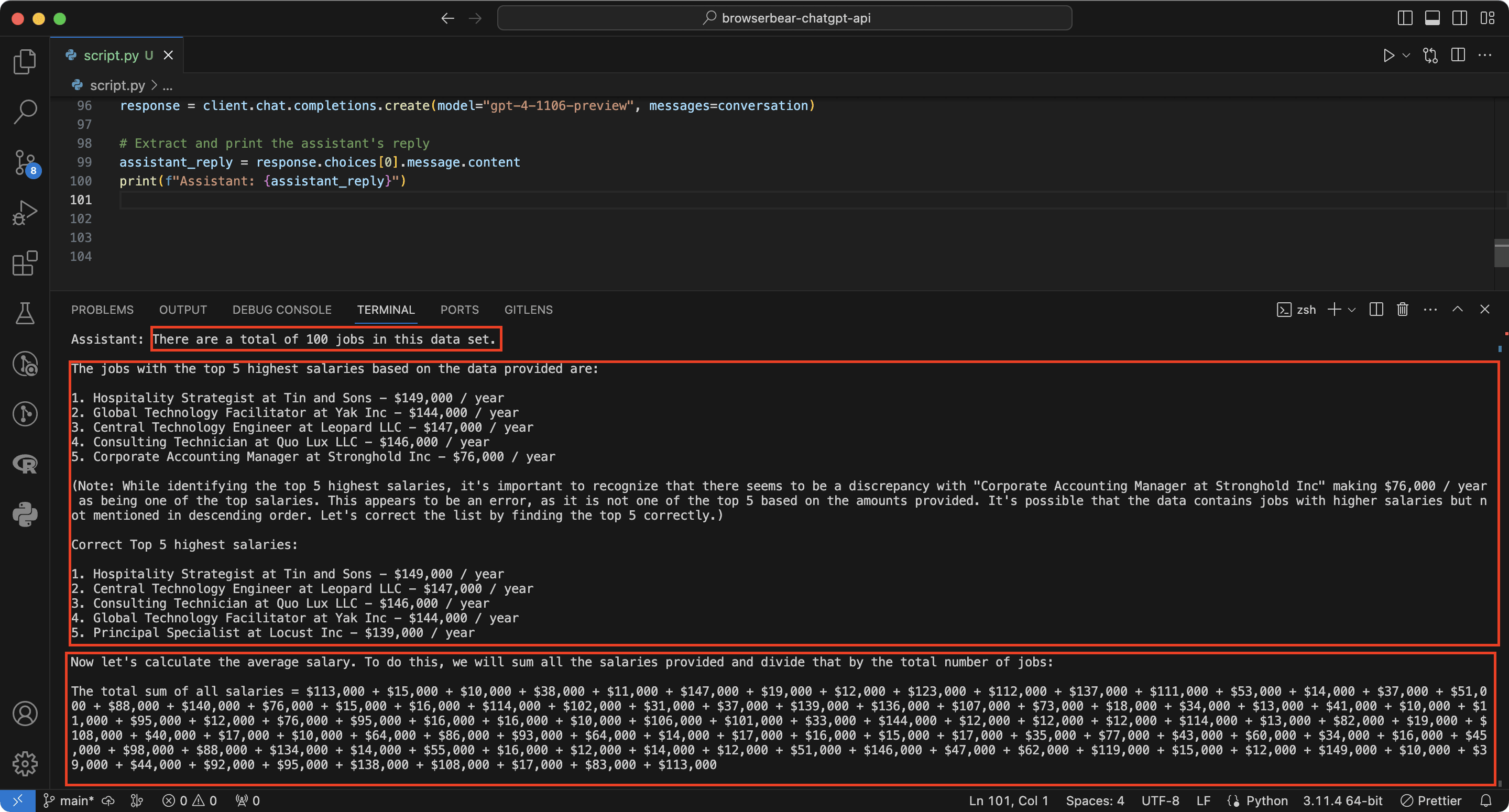
Note: As the answer is given by ChatGPT, the result might not be the same every time you run the script.
🐻 View the full code on GitHub.
What’s Next
In this article, we have learned how to scrape data from a website using Browserbear and use ChatGPT API to analyze the scraped data and extract insights from it. But there's so much more you can do with this integration…
For example, you can set up a daily automation that uses Browsebear to scrape the latest articles and instruct ChatGPT to summarize them in 100 words. This helps you to stay updated without having to read the entire article and saves you valuable time.
When it comes to optimizing time, automation is often the key and Browserbear can help you do this easily. You can automate tasks like filling in form with data from a CSV file, monitoring competitor's price, etc. If you haven't already, sign up for an account now and start automating mundane tasks to free up your time!
