


Everything You Need to Know About the XPath Contains() Function
Contents
In today's fast-paced digital landscape, browser automation has become an indispensable tool for simplifying various web-related tasks. From data scraping to website testing and automating repetitive actions, developers and testers rely on efficient browser automation tools to locate and interact with elements on web pages.
Browser automation tools that are widely used by developers include Selenium, Playwright, and Cypress. These tools support a wide range of programming languages like Java, Python, JavaScript, C#, and more. Besides that, there are also browser automation tools like Browserbear that don’t require coding.
Regardless of which browser automation tool is used, locating an HTML element from a web page is required to interact with the browser interface. Various methods can be used to locate an element, including using CSS Selectors and XPath. In this article, we’ll talk about XPath and one of its most used functions—contains().
What is XPath
XPath, as known as XML Path Language, is an expression language that is used to navigate and select elements in an XML or HTML document. It provides a way to locate elements on a web page based on their tag name , attributes , position , text content , and more in the document’s hierarchy.
The XPath expression is constructed according to the position of the HTML element in the document's hierarchy. It's like a map that leads you to the target from a starting point. Therefore, you can use XPath to locate an element on a web page when its ID, class, name, and other attributes are unavailable and you can’t use DOM.
XPath vs. CSS Selectors: Which One to Use
XPath and CSS Selectors are two methods that are commonly used to locate an HTML element on a web page when using a browser automation tool. To decide which one to use, here are some factors that you should consider:
- Selector availability - CSS Selectors can locate an element directly using its ID, class, name, and other attributes. However, they might not always be available. In this case, you can use XPath to locate an HTML element based on its position in the document hierarchy.
- Readability - Compared to using an absolute XPath that starts from the root element of the document and navigates down the hierarchy of the elements until the target element is found, CSS selectors are shorter. This will keep your code cleaner and easier to read.
- Project requirements - Not all HTML elements can be located using CSS selectors. For example, you might need to find an element based on its text content in some cases. However, you can’t match an HTML element based on its text content using CSS selector but you can do it in XPath, eg.
//h1[text()='Welcome']. - Directional flow - CSS Selectors support one-directional flow for locating an HTML element, traversing elements from parent to child. On the other hand, XPath supports bidirectional flow, meaning traversal can be both ways from parent to child and child to parent as well.
CSS Selectors are simpler and easier to use while XPath is more powerful and provides more advanced features with its built-in functions like text(), position(), and contains(). It's important to note that you're not limited to using just one method in your automation code. If the browser automation tool supports both CSS Selectors and XPath for locating HTML elements, consider utilizing both approaches to maximize their benefits and achieve optimal results.
🐻 The full list of CSS Selectors can be found here.
Using XPath Contains() to Match Text Content
The contains() function takes two arguments, with the first one being the string to be searched and the second one being the string to look for as a substring of the first argument.
contains(arg1, arg2)
When arg2 can be found within arg1, the function will return true. Otherwise, it will return false.
Using it within the [] after the tag name in an XPath expression helps you to locate an HTML element on a web page by checking whether it contains a particular text.
Here's an example that finds h1 elements that contain the text "hello" on a web page:
//h1[contains(text(), 'Hello')
Differences Between text()=‘value’ and contains(text(), ‘value’)
Different from the text() function that needs the entire text to match entirely, contains() returns true even if it matches partially. Given that you need to locate an h1 element with the text value “Hello World”, searching for “Hello” using both functions will give you different results:
Using the text() function
The expression below looks for h1 that matches “Hello” exactly. It will return false if we use it to find the h1 element "Hello World".
//h1[text()='Hello')
Using the contains() function
On the other hand, using the contains() function will return true because the text only needs to be matched partially.
//h1[contains(text(), 'Hello')
However, this will also return other h1 elements that contain the word “Hello”, like “Hello There”, “Hello Kitty”, etc.
🐻 Bear Tips: You can use a wildcard (*) to select all elements regardless of their tag names, eg. //*[contains(text(), 'Hello'].
Different Behaviours Among XPath Versions
There are multiple versions of XPath and different browsers might use different versions. The later versions of XPath extend the capabilities of XPath 1.0 with extra capabilities. For example, XPath 2.0 has added the capability to support a richer set of data types compared to XPath 1.0. That said, the later versions of XPath are backward compatible and nearly all XPath 1.0 expressions can still be used for XPath 2+.
Since there are slight differences in these versions, the functions also behave differently.
XPath 1.0
When using the contains(arg1, arg2) function, arg1 can take in multiple items and it can even be a node set that contains a group of nodes. In this case, the node set will be converted to a string that takes the string value of the first node only.
Using the //*[contains(text(), 'target string')] expression, the element below can be located, as “target string” is the first node.
<div>
<p>target string <br/>other strings</p>
</div>
If it’s not in the first node, the function will return false and the element cannot be located.
<div>
<p>other strings <br/>target string</p>
</div>
XPath 2+
For XPath 2.0 and above, it is an error to call contains(arg1, arg2) with more than one item as the first argument. Therefore, the XPath expression from the previous example will return an error and cannot be used to locate both elements.
Instead of using the previous XPath expression, use this:
//*[text()[contains(., 'target string' )]]
The dot ( “.” ) in XPath refers to a single node. When the dot is used in contains(), it matches the string with every individual node, regardless of its position. Hence, it can be used in XPath 2+ to find the first element, with “target string” as the first node.
Since the position of the string doesn't matter, it will return true for the second element too. This also applies to XPath 1.0.
Using XPath Contains() to Match Attribute Values
Besides using contains() with text(), you can also use it with other HTML attributes like class, href, id, name, etc. to find an HTML element.
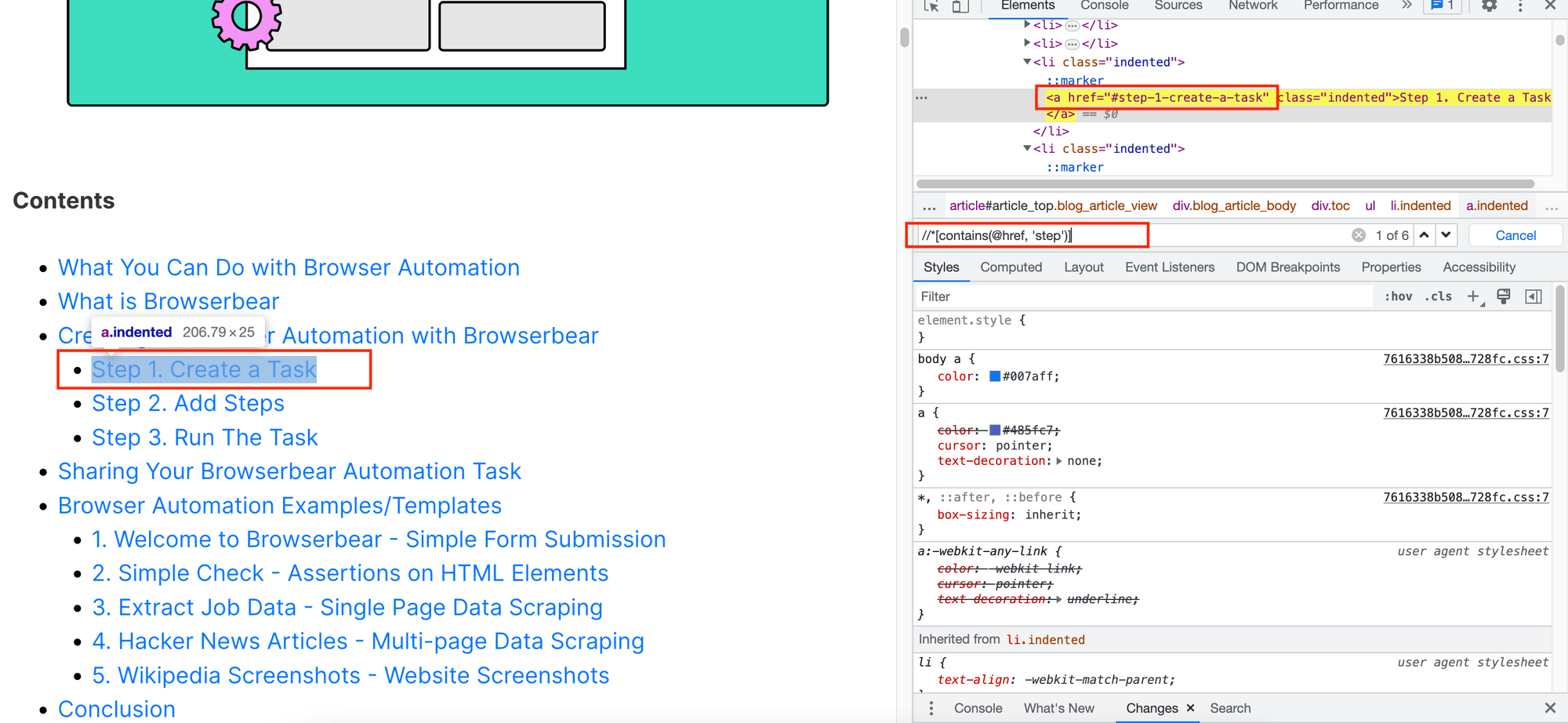
For example, the expression below will look for HTML elements on the web page that have the word “step” in their href value.
//*[contains(@href, 'step')]
The screenshot below shows one of the matched HTML elements:
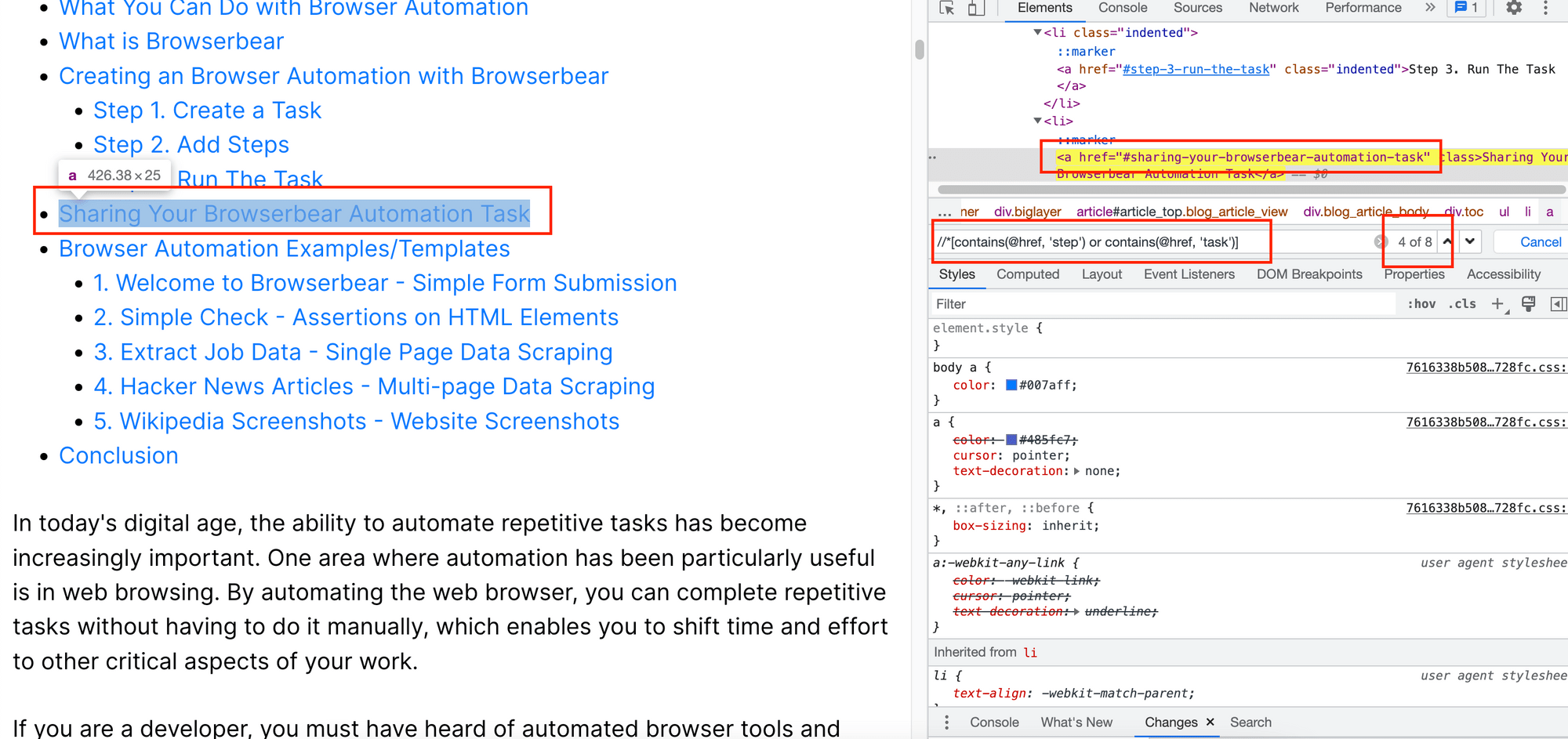
You can even combine multiple conditions using the OR expression:
//*[contains(@href, 'step') or contains(@href, 'task')]
This will return elements that match either one of the conditions:
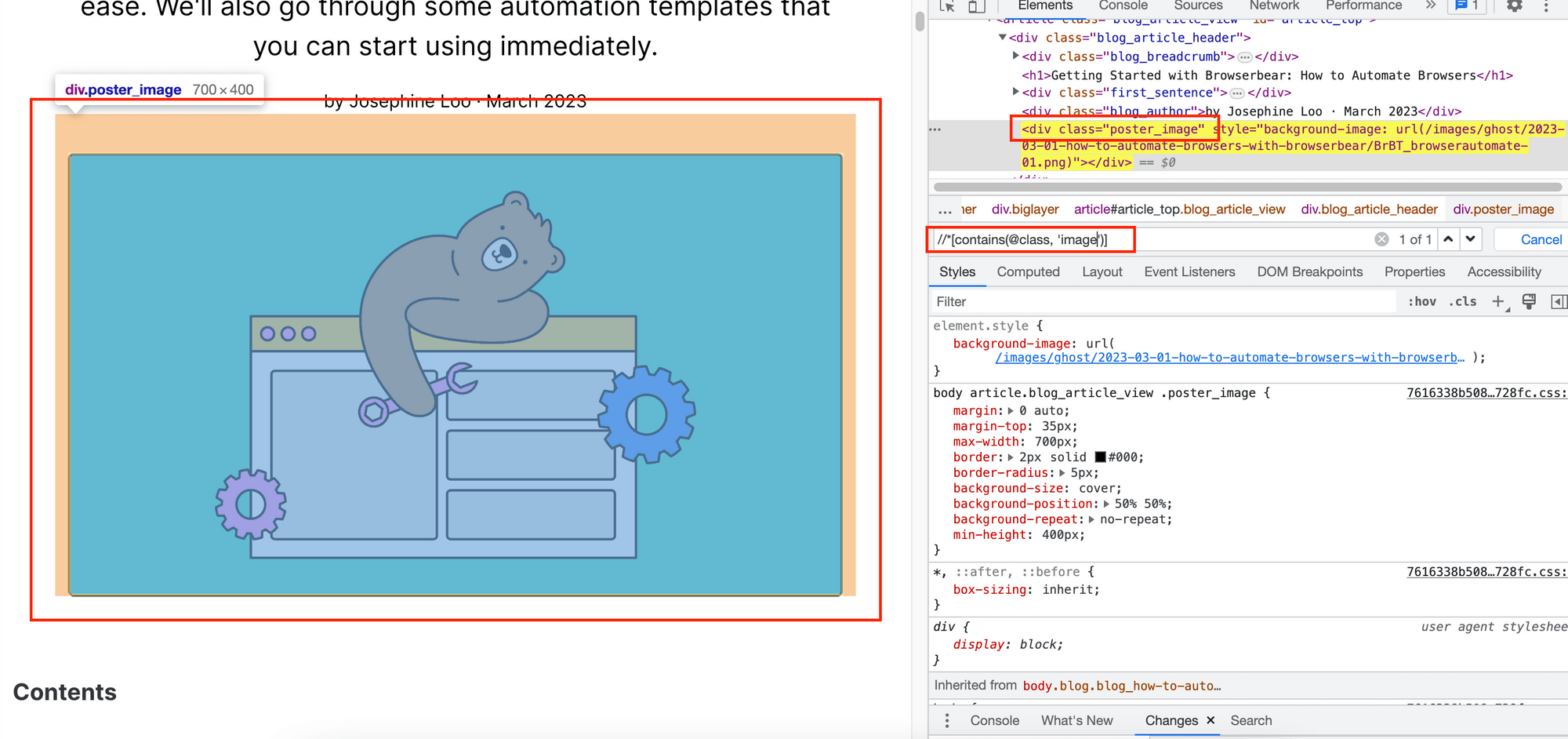
Here’s another example that matches the string with the class values in the HTML document:
//*[contains(@class, 'image')]
Result:
Conclusion
XPath offers various built-in capabilities to help developers locate an HTML element from a web page for automation and the contains() function is just one of them. Understanding the XPath syntax and how to use different functions will help you construct XPath expressions faster. Alternatively, you can use a Chrome extension like Browserbear Helper to generate XPath expressions in a few clicks.
Using the right tools in your workflow can improve your efficiency and productivity. If you’re interested to explore a browser automation tool that can save you lots of time in coding, check out Getting Started with Browserbear: How to Automate Browsers.
